Solutions for each phase of your research data
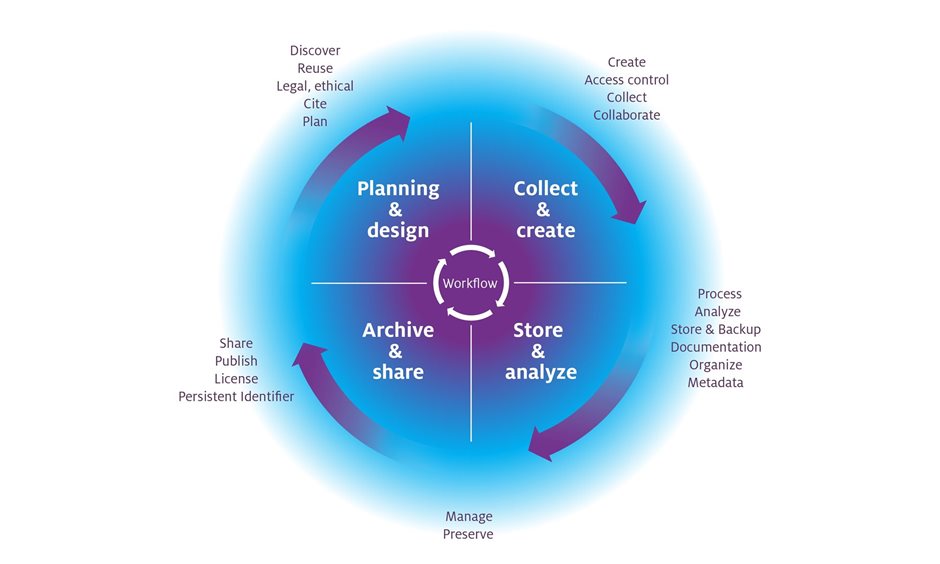
The Research Data Lifecycle (RDL) is our guiding principle for all research data. It guides a researcher through the four stages of research data, all of which are equally important to maximize scientific impact:
- Planning & design
- Collect & create
- Store & analyze
- Archive & share
View in-depth information for each phase, and see which tools apply.
read moreSolutions for each phase of your research data
The Research Data Lifecycle (RDL) is our guiding principle for all research data. It guides a researcher through the four stages of research data, all of which are equally important to maximize scientific impact.
View in-depth information for each phase, and see which tools apply.
-
During planning & design of the research project, all the aspects of data management including the required infrastructure for data collection is set up.
For example, for all data that will be collected the researcher should list the type, format and expected size of the data, as well as how and where it will be stored. This phase is essential when applying for research funding and obtaining ethical approval. During this phase, the research protocol is written and a first draft of the Data Management Plan is set up.
Tools that can be used during this phase (available via intranet)
Also useful
More information and sample texts for data management paragraphs can be found on this RDM webpage by Radboud University.
-
Data collection includes both the creation of new data and the (re)use of existing data sources.
For new data, the research method should be described in the research design. For example, data can be created by means of observations, patient related outcomes or surveys, dossier research or (animal) experimental laboratory studies. The applicable laws and regulations should be checked for each of the methods described in the study design. For instance, it is important to determine the terms and conditions for use of patient data; is an informed consent required, are data sources protected by copyright or licenses?
Document as many characteristics of the data (i.e. metadata) as possible during the data collection phase, to increase Findability, Interoperability and Reusability. This includes characteristics of the data collection as a whole, but also information on record level (e.g. individual patients, participant, animals, batches, etc.) and descriptions of the variables that will be measured for each record. To ensure Interoperability of your data, data standards should be used to describe your (meta)data.
Tools that can be used during this phase (available via intranet)
Also useful
This webpage by FAIRsharing provides an overview of domain-specific data standards in the life, environmental and biomedical sciences. You can also use the webtool ontology recommender, or this webpage by FAIR Cookbook to determine which data standard best fits your study. More information on data reuse, informed consent, ethics, privacy and safety can be found on this RDM webpage by Radboud University.
-
The collected data needs to kept safe and secure, requiring access to good storage and sharing facilities.
For researches at the Radboudumc, the Digital Research Environment (DRE) is the preferred place for temporary storage of your data during the analysis phase of your study. This is a virtual environment that enables researchers to work sustainably and safe throughout all phases of their research; it enables you to import, combine, edit, optimize, save, analyze, archive and share research data with researchers inside and outside the Radboudumc. Working in the DRE allows researchers to comply with the applicable guidelines regarding safe and sustainable collection of research data due to the presence of (amongst others) regulated access, user roles and data safety.
Note that the DRE is not a data repository. For long term storage and sharing your data for reuse in other studies, please refer to the phase 'Archive & Share'.
Tools that can be used during this phase
Also useful
During this phase, data can also be stored in data repositories that offer restricted/under embargo access (see the phase 'Archive & Share' for examples of suitable data repositories). Storing your data in a data repository guarantees that your data is protected from loss or damage. After publication, the embargo can be lifted, making the data quickly accessible for other researchers.
More information on data reuse, informed consent, ethics, privacy and safety can be found on this RDM webpage by Radboud University.
-
To increase the impact of a researcher’s work it is important to publish the raw data and the supporting data analyses in addition to the ‘traditional’ outputs like articles and presentations.
A growing number of funders and journal publishers require the research data to be shared, preferably meeting the FAIR principles to facilitate reuse in other studies.
Data are often stored on a wide range of systems and locations that can potentially change over the years. A sustainable, permanent and unique link to these data preserves its findability, and makes it easier to cite the data and link the data to the researcher that produced the work. There are several systems in use for these so-called persistent identifiers, such as ORCID for authors of scientific literature, ISBN for books and (amongst others) Uniform Resource Name (URN), Persistent URL (PURL) and Digital Object Identifier (DOI) for digital objects. Digital Object Identifiers (DOI’s) are already assigned to articles, but they are increasingly used by research data repositories to identify documents and data.
Published data is not necessarily open data. Sometimes open access cannot be provided for a dataset, because the study is not yet finished, or because of privacy or intellectual property reasons. In those cases, the dataset can be published under embargo, or with restricted access.
Tools that can be used during this phase (available via intranet)
Also useful
More information on data archiving and sharing can be found on this RDM webpage by Radboud University.